
This marks the first such case in India, but the lack of clear policies on AI’s use of public data has sparked similar conflicts globally. At the core of the issue is AI tools’ relentless demand for high-quality data. However, their reliance on readily available online information is nearing its limit. Without expanding their data sources—such as printed novels, personal documents, videos, and copyrighted news content—the growth of AI chatbots could plateau.
This pursuit of data, however, is colliding with copyright concerns and the carefully constructed business models of publishers and media outlets.
Read this | Mint Explainer: The OpenAI case and what’s at stake for AI and copyright in India
The story so far
In the US, publishers, musicians, and authors have taken legal action against AI companies for using copyrighted content to train their models. Last year, Getty Images sued Stability AI, accusing it of using 12 million of its photos to develop its platform. Similarly, The New York Times filed a lawsuit against OpenAI, alleging the misuse of its content and positioning the AI company as a direct competitor in providing reliable information. Several writers have also initiated lawsuits with similar claims.
AI companies, however, largely argue that their language models are built on publicly available data, which they contend is protected under fair use policy.
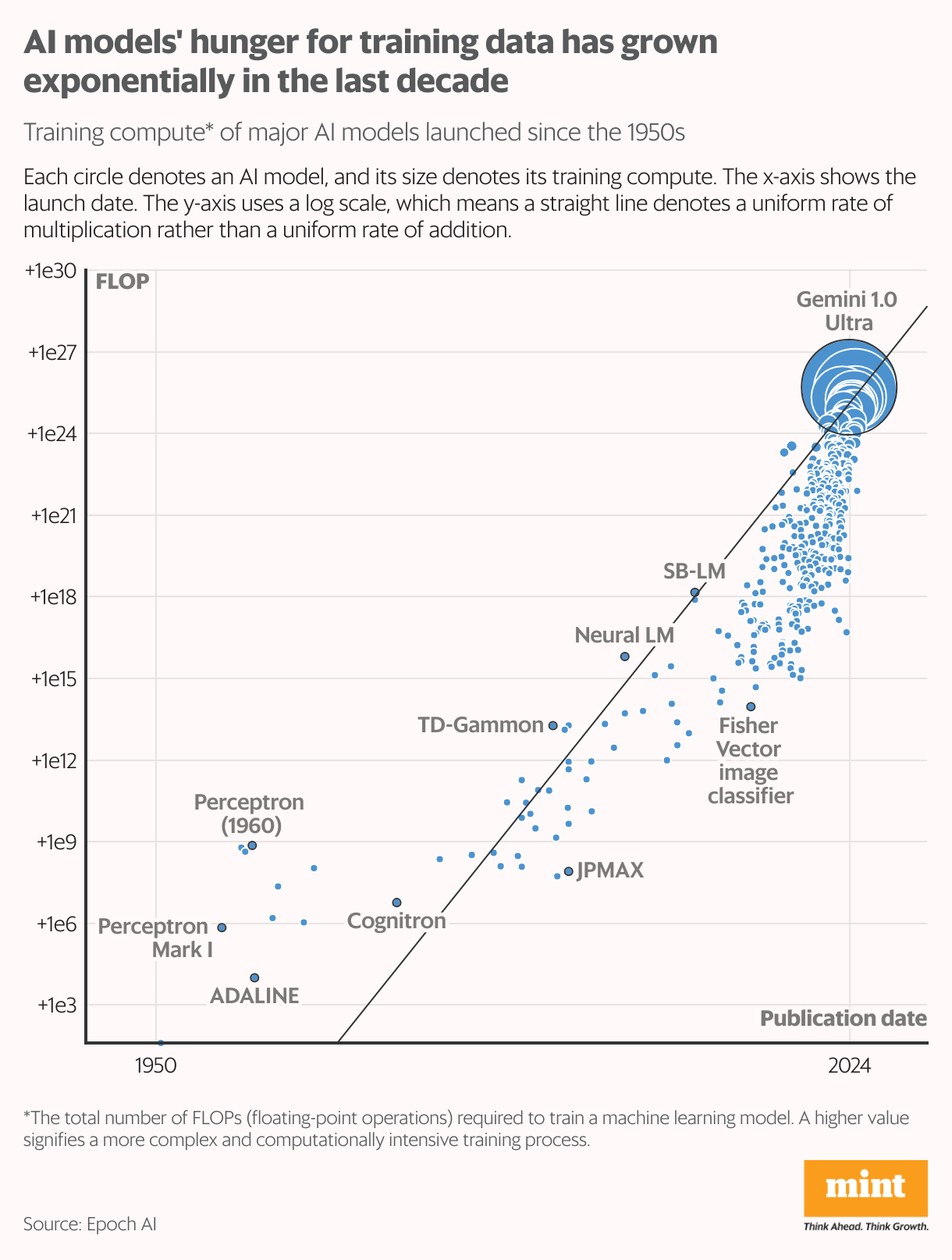
After being trained on massive datasets, advanced AI models like OpenAI’s ChatGPT 4.0 and Google’s Gemini 1.0 Ultra have achieved computational efficiency comparable to, if not surpassing, the human brain. Some of these models have even outperformed humans in tasks such as reading, writing, predictive reasoning, and image recognition.
Read this | OpenAI vs ANI: Why ‘hallucinations’ are unlikely to go away soon
To deliver precise, error-free, and human-like outputs, AI systems require vast amounts of human-generated data. The most advanced models, such as these two, are trained on trillions of words of text sourced from the internet. However, this pool of data is finite, raising questions about how these models will sustain their growth as readily available information runs out.
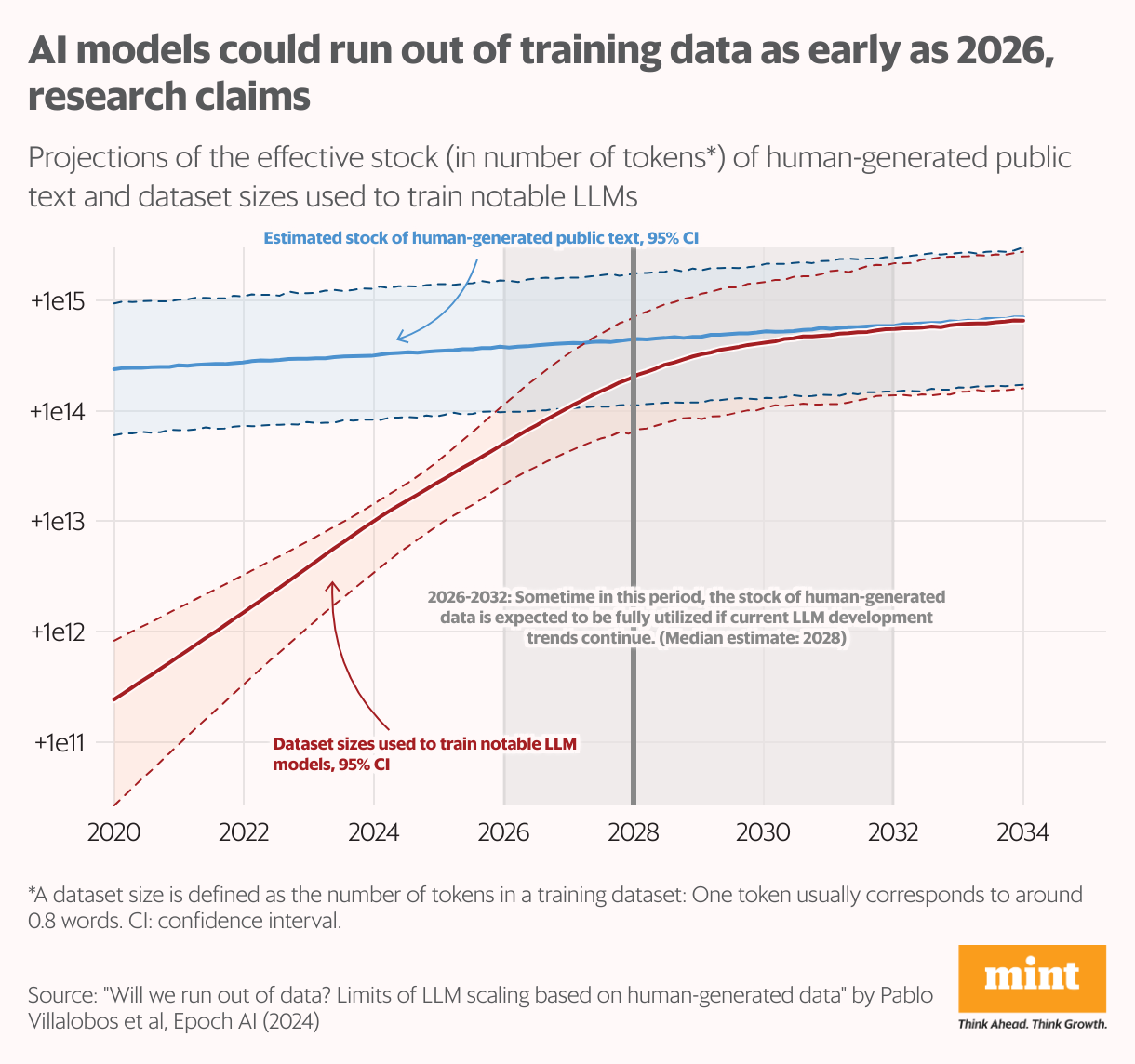
Researchers at Epoch AI estimate the internet holds around 3,100 trillion “tokens” of human-generated data—though only about 10% is of sufficient quality to train AI models. (A token, in this context, is a fundamental text unit, such as a word, used by AI models for learning.) This stockpile is growing at a sluggish pace, and as large-language models continue to scale, they are projected to exhaust this data supply between 2026 and 2030, according to an Epoch AI study published earlier this year.
OpenAI, facing a data shortage just before ChatGPT’s 2022 launch, turned to unconventional methods. According to a New York Times report in April this year, it created Whisper, a speech recognition tool that transcribed millions of hours of YouTube videos into text, potentially breaching Google’s terms and the rights of content creators. Google itself allegedly did the same, and expanded its privacy policy to allow itself to tap into files in Google Docs and Sheets to train its bots.
The hunt
With data in limited supply, AI companies are scouring every possible source to feed their models. Students’ assignments, YouTube videos, podcasts, online documents and spreadsheets, social media posts—nothing escapes the ravenous search for data by tech giants.
This relentless pursuit has fuelled fierce competition among AI companies to secure lucrative data deals with publishers, often worth millions of dollars. For instance, Reddit struck a $60 million annual deal with Google, granting the tech giant real-time access to its data for model training. Legacy publishers like Wiley, Oxford University Press, and Taylor & Francis, as well as news agencies such as Associated Press and Reuters, have also inked agreements with AI firms, with some deals reportedly reaching multi-million-dollar valuations.
Also read | Mint Explainer: What OpenAI o1 ‘reasoning’ model means for the future of generative AI
As human-generated data becomes increasingly scarce and challenging to source, AI companies are turning to synthetic data—information created by AI models themselves, which can then be reused to generate even more AI data. According to research firm Gartner, synthetic data is projected to surpass human-generated data in AI models by 2030.
While synthetic data offers immense potential for AI companies, it is not without risks. A study published in Nature in July 2024 by Ilia Shumailov and colleagues highlights the danger of “model collapse.” The research found that when AI models indiscriminately learn from data generated by other models, the output becomes prone to errors. With each successive iteration, these models begin to “mis-perceive” reality, embedding subtle distortions that replicate and amplify over time. This feedback loop can cause outputs to drift further from the truth, compromising the reliability of the models.
There have also been attempts to improve the algorithmic efficiency of AI models, which will allow them to be trained on a lesser amount of data for the same output.
Small language models (SLMs), which are used for performing specific tasks using less resources, have also become popular as they help AI companies by not relying on massive troves of data to train their models. A case in point, AI company Mistral’s large language model 7B is built using 7 billion parameters and the company claims it outperformed the LLM model Meta’s Llama 2 built on 13 billion parameters on all benchmarks.
Also read | India’s generative AI startups look beyond building ChatGPT-like models
The rat race of chatbots to outsmart each other—and the human brain—is shaping the future of technology. As AI companies grapple with data scarcity and copyright battles with publishers, the ethical implications of their data-hungry pursuits are looming large.

